1. 데이터 인코딩의 개요
인공지능에서 데이터를 처리하거나 모델에 입력하기 위해서는 적절한 형태로 변환할 필요가 있습니다. 특히, 범주형 데이터는 숫자 형태로 변환해야 합니다. 이를 위해 사용되는 대표적인 방법이 레이블 인코딩(Label Encoding)과 원-핫 인코딩(One-Hot Encoding)입니다. 이 글에서는 각 인코딩 방법의 개념과 예제, 그리고 분석 방법을 알아봅니다.

2. 레이블 인코딩
레이블 인코딩은 범주형 데이터를 숫자로 변환하는 가장 간단한 방법입니다. 각 범주에 고유한 정수를 할당하고, 이를 데이터에 적용합니다. 이 방법은 다음과 같은 순서로 진행됩니다.
- 범주형 데이터의 모든 고유한 범주를 찾습니다.
- 고유한 범주에 대해 0부터 시작하는 정수를 할당합니다.
- 각 데이터를 해당하는 정수로 변환합니다.
예를 들어, 성별을 나타내는 범주형 데이터가 있다고 가정해봅시다. 남성(Male)과 여성(Female) 두 가지 범주를 가지고 있으며, 이를 레이블 인코딩으로 변환하면 다음과 같습니다.
- Male: 0
- Female: 1
이 방법의 단점은 숫자로 변환된 범주 간에 순서가 생겨서 모델이 이를 잘못 해석할 수 있다는 것입니다. 예를 들어, 세 가지 색상 데이터를 레이블 인코딩으로 변환하면 다음과 같습니다.
- Red: 0
- Blue: 1
- Green: 2
여기서 모델이 Blue와 Green 사이의 관계가 Red와 Blue 사이의 관계보다 더 가깝다고 해석할 수 있습니다. 이 문제를 해결하기 위해 원-핫 인코딩을 사용할 수 있습니다.
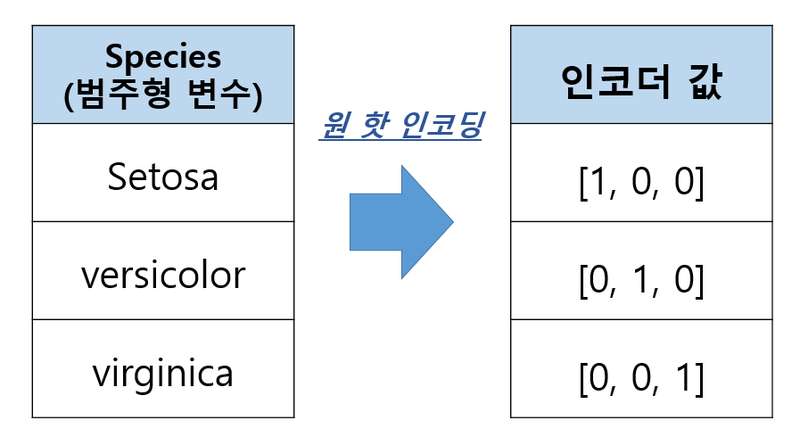
3. 원-핫 인코딩
원-핫 인코딩은 각 범주를 고유한 이진 벡터로 변환하는 방법입니다. 이 방법은 다음과 같은 순서로 진행됩니다.
- 범주형 데이터의 모든 고유한 범주를 찾습니다.
- 각 범주에 대해 벡터를 생성하고, 해당 범주의 인덱스에서만 1을 할당하고 나머지 인덱스에는 0을 할당합니다.
- 각 데이터를 해당하는 범주의 이진 벡터로 변환합니다.
위의 색상 예제를 원-핫 인코딩으로 변환하면 다음과 같습니다.
- Red: [1, 0, 0]
- Blue: [0, 1, 0]
- Green: [0, 0, 1]
이 방법은 각 범주가 독립적인 관계를 가지게 되므로, 모델이 범주 간의 관계를 잘못 해석하지 않습니다. 그러나 원-핫 인코딩은 범주의 수가 많을 경우 메모리를 많이 사용할 수 있는 단점이 있습니다.
4. 데이터 인코딩 선택하기
데이터 인코딩 방법을 선택할 때는 주어진 데이터와 모델에 맞는 방법을 사용해야 합니다. 레이블 인코딩은 간단하게 범주형 데이터를 숫자로 변환할 수 있으나, 범주 간의 순서 관계가 문제가 될 수 있습니다. 반면 원-핫 인코딩은 독립적인 관계를 가지므로 이러한 문제를 해결할 수 있으나, 메모리 사용이 비효율적일 수 있습니다. 따라서 다음과 같은 경우에 적합한 인코딩 방법을 선택해야 합니다.
- 순서가 있는 범주형 데이터: 레이블 인코딩
- 순서가 없는 범주형 데이터: 원-핫 인코딩
5. 데이터 인코딩 예제: 파이썬 라이브러리 사용하기
파이썬에서 레이블 인코딩과 원-핫 인코딩을 적용하기 위해 scikit-learn 라이브러리를 사용할 수 있습니다. 다음은 이를 사용한 간단한 예제입니다.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 레이블 인코딩
le = LabelEncoder()
label_encoded_data = le.fit_transform(["Red", "Blue", "Green"])
# 원-핫 인코딩
ohe = OneHotEncoder()
one_hot_encoded_data = ohe.fit_transform(label_encoded_data.reshape(-1, 1)).toarray()
6. 데이터 인코딩 후의 전처리 및 분석
데이터 인코딩이 완료된 후에는 추가적인 전처리 및 분석이 필요할 수 있습니다. 예를 들어, 인코딩된 데이터를 기반으로 결측치 처리, 이상치 탐지, 데이터 스케일링 등의 작업을 수행할 수 있습니다.
7. 다른 인코딩 방법
레이블 인코딩과 원-핫 인코딩 외에도 다양한 인코딩 방법이 있습니다. 몇 가지 대표적인 방법은 다음과 같습니다.
- 순서 인코딩 (Ordinal Encoding): 범주형 데이터가 순서를 가지고 있을 경우 사용할 수 있는 인코딩 방법입니다. 각 범주에 순서에 따라 정수를 할당하며, 이를 통해 모델이 순서 정보를 학습할 수 있습니다.
- 타겟 인코딩 (Target Encoding): 타겟 변수를 기준으로 각 범주의 평균값을 계산하여 범주를 숫자로 변환하는 방법입니다. 이 방법은 회귀 문제나 분류 문제에서 특히 유용하게 사용할 수 있습니다.
- 바이너리 인코딩 (Binary Encoding): 범주를 이진 코드로 변환한 후, 이를 다시 정수로 변환하는 방법입니다. 원-핫 인코딩보다 메모리 효율이 좋으며, 범주가 많은 경우에 사용할 수 있습니다.
각 인코딩 방법은 특정 상황에 적합하므로, 데이터와 문제에 맞는 방법을 선택하여 사용해야 합니다.
8. 인코딩 후 모델 학습 및 평가
데이터 인코딩이 완료되면, 인코딩된 데이터를 사용하여 모델을 학습시키고 평가할 수 있습니다. 인코딩된 데이터를 학습 데이터와 검증 데이터로 나누어 모델의 성능을 측정하고, 하이퍼파라미터 튜닝 등의 작업을 수행하여 최적의 모델을 찾을 수 있습니다.
9. 결론
인공지능에서 데이터 인코딩은 범주형 데이터를 모델이 이해할 수 있는 형태로 변환하는 중요한 전처리 작업입니다. 레이블 인코딩, 원-핫 인코딩 등 다양한 인코딩 방법을 알아보았으며, 각 방법의 장단점과 적용 상황을 이해하였습니다. 데이터 전처리 및 인코딩 작업을 통해 모델의 성능을 향상시킬 수 있으므로, 적절한 인코딩 방법을 선택하여 사용하는 것이 중요합니다.
'머신러닝' 카테고리의 다른 글
| 인공지능에서 교차 검증 기법 소개 (0) | 2023.04.28 |
|---|---|
| AI에서의 특성 스케일링 (0) | 2023.04.28 |
| 인공지능에서 분류와 회귀 이해하기 (0) | 2023.04.28 |
| 인공지능에서 변수의 개념 및 활용 이해하기 (0) | 2023.04.27 |
| Matplotlib 기초와 활용: 파이썬 데이터 시각화 도구 (0) | 2023.04.27 |